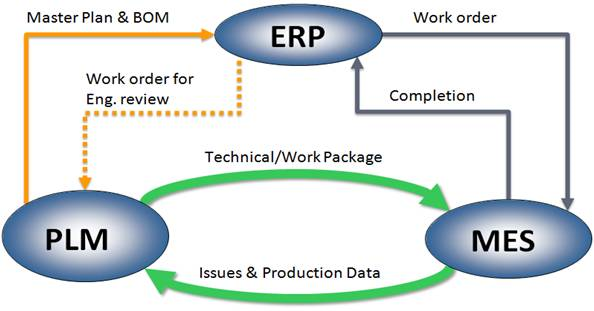
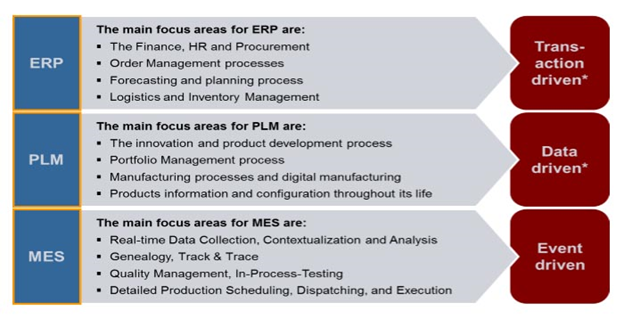
3 Pillars of Manufacturing Information System
From data integration to Data Science, we have all data related services you may need.
From Data Hub, ESB to Application orchestration, we bring the seamless harmony for enterprises
Read MoreData Warehousing, Data Lake, Data Analytics and Business Intelligence
Read MoreExpert in Data Service Domain with the right solutions and the right cost!

Bring enterprise data from different silos together and seamlessly link them for a 360 views of our whole business, which has been hindering our business for a long time!
Tech insights from the industry insiders
I think you already have heard about data lakes. They used be called data directories. As you would expect, Data Rivers end up their “streams” in the lake. Here we go with data ponds:Connected Data Ponds: The Evolution of Data Lakes – HortonworksA lot has been said about Data Lakes over the past five years. The call to action from our industry to customers was to…hortonworks.com
Data ponds are subsets of data lakes that are separated for privacy (i.e. PII), governance, technology or costs.
Data droplets are the basic element. They describe information and dimensions about the subject. Here you can read more about these ontologies.
Then, we have data swamp. Larger organizations have this issue as a more severe one. The image below explains the differences:
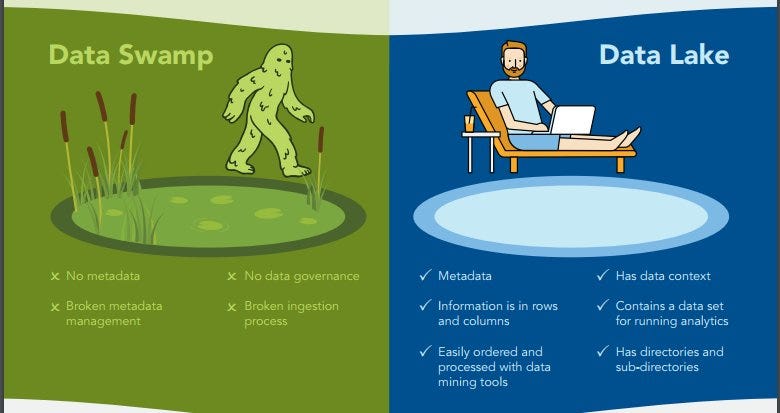
There are many reason behind a data swamp, below are a few:
Bigger companies have started to find a solution for this issue. Metacat from Netflix help to understand the metadata in different services, or if you want to keep it simple with an user interface, CKAN data portal can help you manage and govern your data.
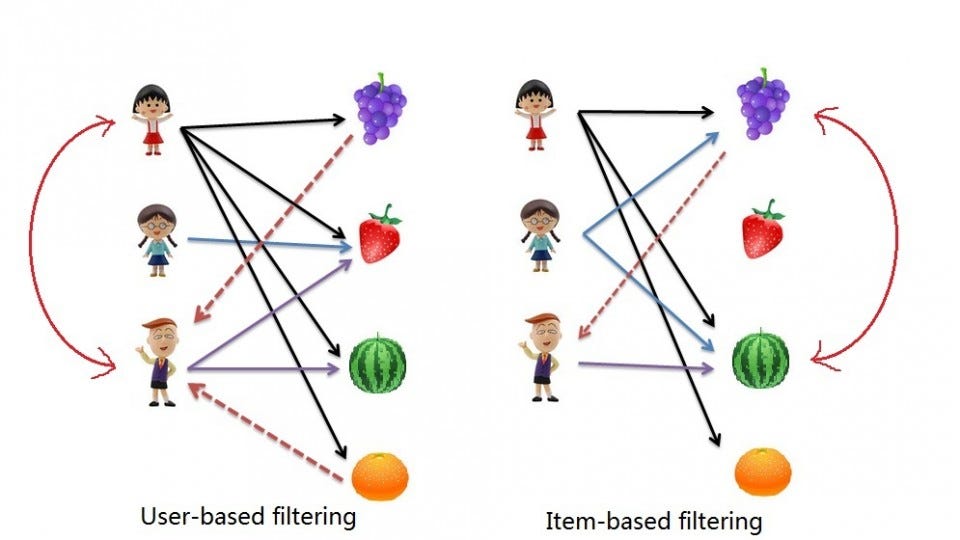
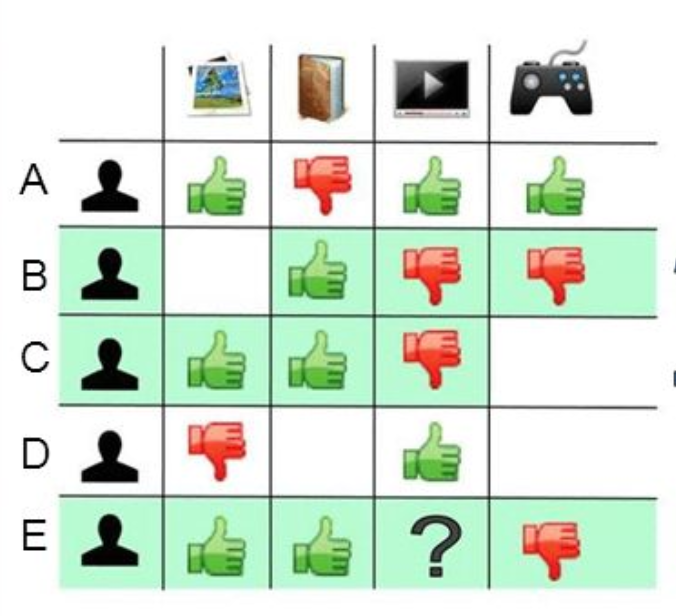
Imagine that we want to recommend a movie to our friend Stanley. We could assume that similar people will have similar taste. Suppose that me and Stanley have seen the same movies, and we rated them all almost identically. But Stanley hasn’t seen ‘The Godfather: Part II’ and I did. If I love that movie, it sounds logical to think that he will too. With that, we have created an artificial rating based on our similarity.
Well, UB-CF uses that logic and recommends items by finding similar users to the active user (to whom we are trying to recommend a movie). A specific application of this is the user-based Nearest Neighbor algorithm. This algorithm needs two tasks:
1.Find the K-nearest neighbors (KNN) to the user a, using a similarity function w to measure the distance between each pair of users:
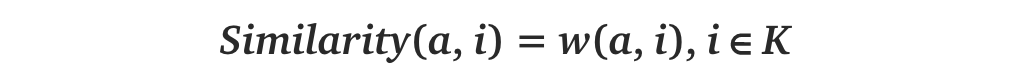
2.Predict the rating that user a will give to all items the k neighbors have consumed but a has not. We Look for the item j with the best predicted rating.
In other words, we are creating a User-Item Matrix, predicting the ratings on items the active user has not see, based on the other similar users. This technique is memory-based.